
De volgende stap van de cel: reproduceren. De cel maakt kopieën van zich zelf. Al heel snel bestaat de soep dan uit een soep van cellen. Lang verhaal kort: de omgeving verandert en dus moeten de cellen zich gaan aanpassen. Een van de belangrijkste aanpassing, is de “uitvinding” van RNA/DNA, om de voorschriften voor cellen vast te leggen. (Ja, RNA/DNA is een latere innovatie dan eiwitsynthese, een soort “reverse engineering“. Ook dat verhaal volgt later).
Von Münchausen revisted
De truc is: bouw zelf zelfrefererende, zelforganiserende, zelfwerkende systemen. Bouw en onderhoud cellen, “Markov dekens”, met daar binnen Markov dekens, dekens binnen lakens kortom, een hele Markov uitzet. De truc wordt herhaald: cellen vormen meercellige organismen, organismen vormen organen. Organisch ontstaat daaruit een levende planeet. Stap voor stap, zonder plan, alleen op basis van voorwaardelijke kansen. Wanneer iets kan gebeuren, gebeurt het uiteindelijk.
Je ziet zo, hoe de hele omgeving uiteindelijk vervangen is door leven. De uiteindelijke Markov deken, noemen we de troposfeer, ongeveer de atmosfeer. Die laatste bestaat voor een groot deel uit zuurstof, een goede truc om anaerobe bacteriën de nek m te draaien ten bate van meercellig leven. Inmiddels heeft het leven de volgende stap gezet met het uitvinden van hulpmiddelen (tools) en, als spin-off, talen. Zoals je hier kunt lezen.
Gedragen gedrag wint de prijs
Markov ketens gedragen zich als een soort kansberekening machine. Dit type wiskunde heet Baysesiaanse statistiek, het berekenen met voorwaardelijke kansen. De statistiek valt intuïtief niet mee. Het bekende voorbeeld is de quizmaster, die je drie keuzes geeft. Achter een ervan zit je prijs. Je kiest, laten we zeggen, deur A. Kans 33%. Voordat de deur opengaat, opent de quizmaster een van de andere twee deuren. Daar zit niets achter. Moet je nu van deur verwisselen of niet?
Intuïtief zou je denken, het maakt niet uit. De kansen lijkt nog steeds 33%. Maar, wanneer je de goede deur met de prijs hebt, heeft de quizmaster twee mogelijkheden om een andere deur te openen. Wanneer je de verkeerde deur hebt, heeft hij er maar één. De kans op de verkeerde deur bij hem, is groter dan de kans op de goede. Dus de quizmaster heeft een kans van 66% op maar één deur. Hij heeft er een open gemaakt waar niets achter zit. De kans dat jij de verkeerde deur hebt, is groter geworden, door de extra informatie. Je kunt dus beter verwisselen van deur.
Wat nog veel gekker klinkt, is dat een zelfrefererend systeem dit vanzelf zal leren – mits er voldoende “tijd” beschikbaar is. Zelfs wanneer een systeem onder een Markov deken niet weet, dat er prijzen te winnen zijn, zal het leren de prijzen te winnen. Door het spel vaak te spelen. Ik zal later ingaan op de rol van “tijd”.
Universele structuur
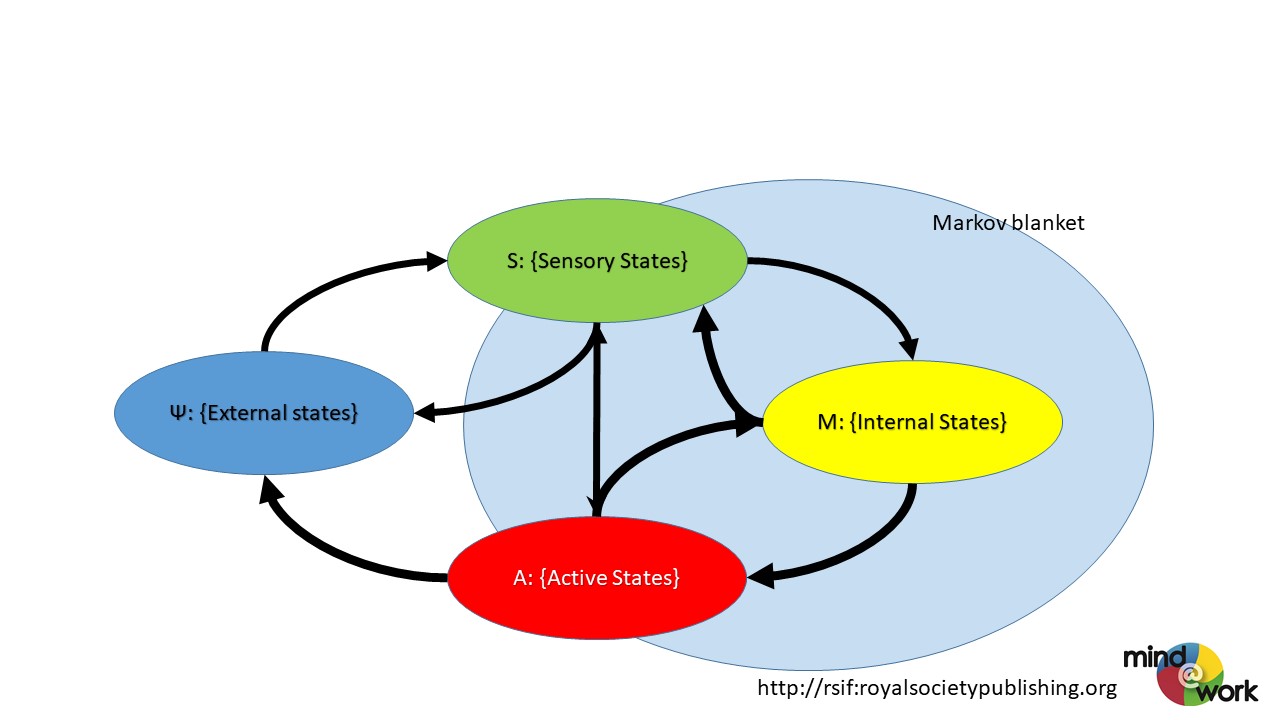 Om te overleven – de hoofdprijs -, moet een cel zich op de volgende manier organiseren:
Om te overleven – de hoofdprijs -, moet een cel zich op de volgende manier organiseren:
– een zelf gemaakt Markov deken of celwand als bescherming tegen de verzameling toestanden Psi, uit de omgeving
– een zintuiglijk waarnemingssubsysteem, S, wat kan corresponderen met toestanden Psi
– een intern modelleringssubsysteem, M, wat kan beoordelen wat er waargenomen wordt en kan besluiten tot prioriteiten in acties
– een actiesubsysteem Q (ik denk dan aan Quarter Master), dat kan ingrijpen op de omgeving Psi en op systeem S
– systemen van overdracht tussen de subsystemen C’s, die zowel het geheel onderhouden, als de subsystemen onderling op elkaar laat afstemmen (tweede orde leren). Wie de schrijver dezes kent, zal beseffen, dat ik niet voor niets het woord “onderhoud” gebruik.
M van Mind
Cruciaal in het spel, is het systeem M. M staat voor Model, of Moeder, of Mind of gewoon M, je weet wel van 007. M optimaliseert de kans op overleven van het geheel, zonder dat M in direct contact staat met de omgeving Psi. M maakt zich tot een model van de omgeving. M verwerkt de indrukken van S via een beoordeling – op basis van voorwaardelijke kansen -, tot prioriteiten van acties voor Q. M, zoals alle managers, voert ze niet zelf uit. Je ziet, dat ik de theorie kan onderbouwen met James Bond (vandaar de 7 in 007), maar je kan het ook nalezen in Bayesian Decision Theory (BDT)

